ML Lecture 3 Part II Data Preparation
数据准备 Data Preparation
概览 Overview
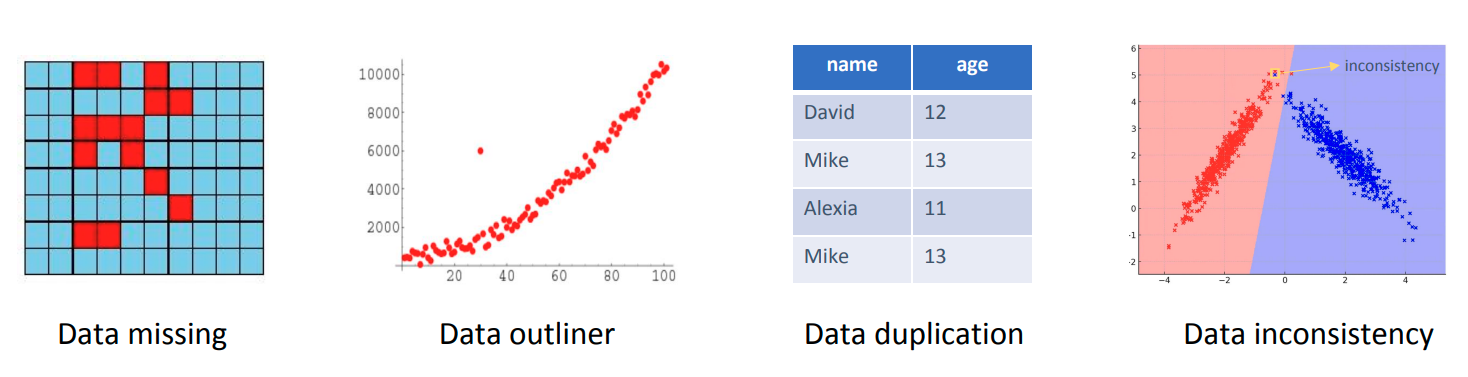
原始数据可能存在的问题
- 数据缺失 Data missing
- 数据中存在离群点 Data outlier
- 数据重复 Data duplication
- 数据不一致Data inconsistency
缺失数据处理:删除与填补方法 Missing Data Processing: Removal and Impute Method
方法一:删除样本
当某个样本缺少某个字段时,将该样本删除。
前提条件:缺失比例小于 5%。
优点:操作简单。
缺点:对于 MAR 和 MNAR 类型的缺失,可能引入偏差。
MAR(随机缺失)的性质是“有迹可循”,数据丢失的原因可以通过其他已有的变量来解释,比如因为是女性所以没填体重,这种缺失通常可以利用现有数据进行推断和修补。 而 MNAR(非随机缺失)的性质是“刻意隐瞒”,数据丢失的原因直接取决于缺失值本身的大小,比如因为收入太高或太低故意不填,这种缺失无法通过现有数据推断,会造成严重的系统性偏差。 简单来说,两者的核心区别在于:MAR 的缺失线索藏在别的列里,它是可修复的;而 MNAR 的缺失线索被它自己带走了,极难还原。
方法二:估计缺失值 当某个样本缺少某个字段时,对该字段进行估计填补。
估计方法:
用统计指标估计(如均值/中位数/众数);
使用机器学习方法(如 KNN)。
优点:可以充分利用已有数据。
缺点:可能产生不准确的数据。
离群值去除:Z 分数方法与 IQR 方法 Outlier Removal: the Z-Score and IQR Method
识别和去除离群值
- 对于服从或接近高斯分布的数据,使用 Z 分数方法。
- 对于高斯或非高斯分布的数据,可以使用百分位数和四分位距(IQR)方法。
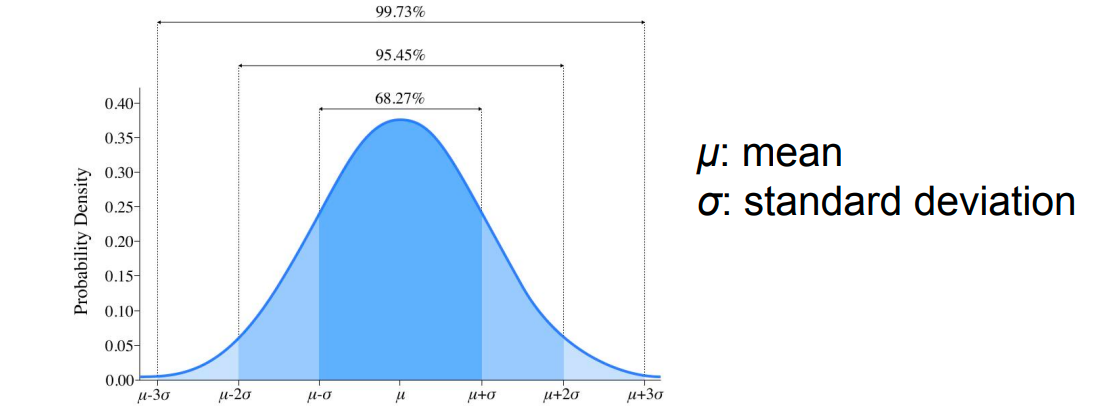
高斯分布与偏度 Gaussian Distribution & Skewness
高斯分布的 p.d.f 为:
 显然有:
显然有:
- 概率分布关于均值对称;
- 靠近均值的数据点出现得更频繁。
偏度 Skewness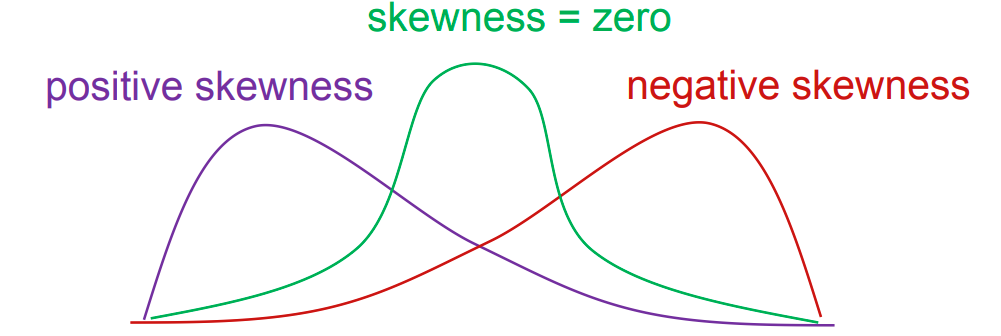
- 对称分布的偏度为 0;
- 负偏度 Negative Skewness:左侧尾部更长;
- 正偏度 Postive Skewness:右侧尾部更长。
Gaussian distribution: symmetrical, zero skewness
高斯分布:对称、偏度为 0。
Z 分数方法 Z-Score Method
其中:
:数据点 :均值 :标准差 : Z 分数
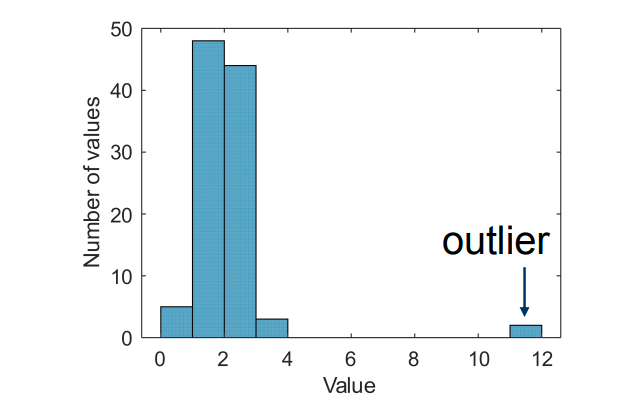 Z 分数表示该数据点与均值之间相差了多少个标准差。 数据点离均值越远,它是离群点的可能性就越大。
Z 分数表示该数据点与均值之间相差了多少个标准差。 数据点离均值越远,它是离群点的可能性就越大。
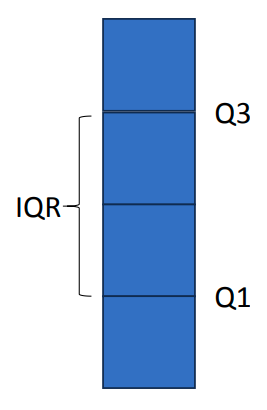
IQR 方法 (四分位距方法)
四分位距 Interquartile Range 即数据从25%到75%的区间长度。
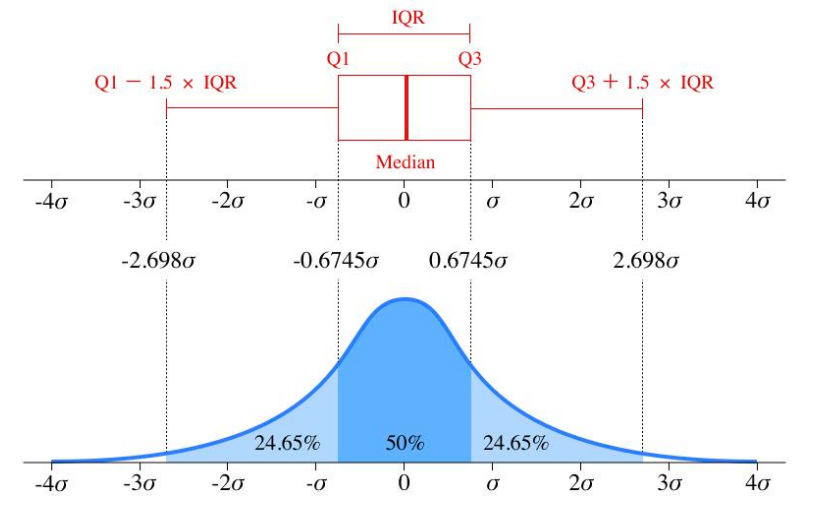
- 认为超出
- 在非高斯分布的数据中同样适用。
数据重复与不一致 Data Duplication and Dnconsistency
| 不一致类型 | 示例 | 修正方法 |
|---|---|---|
| 格式不一致 (Inconsistent format) | 日期 “2023/01/01” vs “01-Jan-2023” | 统一为标准格式 |
| 单位不一致 (Inconsistent units) | 温度 “30° C” vs “86° F” | 转换为相同单位 |
| 命名不一致 (Inconsistent naming) | “New York” vs “New York City” | 创建映射表或使用正则表达式 |
| 逻辑不一致 (Inconsistent logic) | 年龄 “150 岁” 或 “-5 岁” | 基于业务规则进行修正(例如:截断至合理范围) |
| 数值不一致 (Inconsistent values) | 同一个人的年龄不同 | 移除样本(如果占比少于 5%) 根据实际情况选择一个选项(例如:保留来自权威来源的数据等) |
数据变换:归一化、标准化、幂变换 Data Transform: Normalization, Standardization, Power Transform
数据变换 Data Transform包括缩放数值范围、调整分布形状等操作,目的是让数据更适合后续模型学习。
- 数据归一化 Normalization;数据标准化 Standardization。
- 幂变换 Power Transform :处理偏度问题。
数据归一化与标准化
简单来说:
- 归一化 (Normalization) 是把数据压缩到一个固定的区间(通常是 0 到 1)。
- 标准化 (Standardization) 是把每个特征平移并缩放到均值为 0、标准差为 1;它不会自动把非正态数据变成正态分布。
进行归一化和标准化的原因
在机器学习中,不同特征的数值范围可能完全不同,例如:年龄 0–100,收入 0–1,000,000。
如果不进行归一化,可能会出现:
- Slow convergence of gradient descent algorithms: 梯度下降类算法收敛较慢,因为在不同方向上的步长不一致(如 SGD、神经网络等);
- Biased distance/similarity calculations: 距离或相似度计算会被数值范围较大的特征主导(如 KNN、K-Means 等);
- Model weight imbalance: 线性回归、SVM 等模型可能会给数值较大的特征分配更高的权重,从而造成偏倚。
Normalization: Unify the ranges of different data values into a fixed range.
归一化:把不同特征的数据范围统一映射到一个固定的区间。
归一化的使用场景
是否需要归一化/标准化主要取决于输入特征的尺度和所用模型,而不是输出是否为连续数值型。KNN、K-Means、SVM、神经网络、正则化线性模型等通常会受特征尺度影响。
对测试集做归一化时,必须使用训练集的统计量(如均值、标准差、最小值等)。
这样可以避免数据泄露 Data Leakage。
类别型或文本数据不需要归一化。
类别特征需要进行编码,但不必做归一化。
Z 分数标准化 (当服从高斯分布)
将数据转换为均值为 0、标准差为 1 的分布:
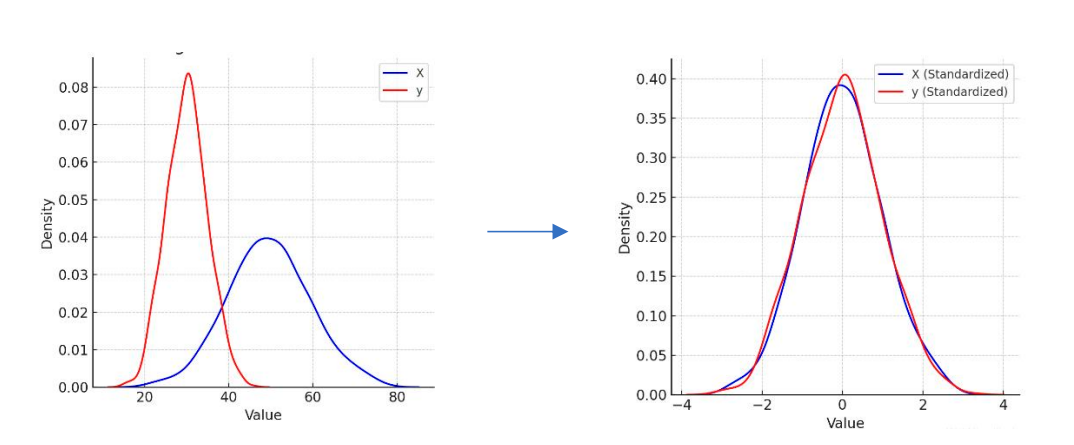 优点
优点
- 在大多数场景下都适用。
缺点:
- 效果最好的是在数据接近正态分布时;
- 输出数据范围不是固定区间。
Min-max 归一化 Min-max Normalization
将数据线性映射到
 优点:
优点:
- 确保数据被规范 regularized 到一个固定的范围。
缺点:
- 仅在数据分布比较均匀 relatively evenly 时效果较好;
- 对离群点非常敏感。
鲁棒缩放归一化 Robust Scaling Normalization
使用中位数和四分位距(IQR)代替均值和标准差,以减小离群点的影响。
 优点: 对离群点干扰具有更好的鲁棒性。
优点: 对离群点干扰具有更好的鲁棒性。
缺点: 计算略微复杂一些。
幂变换 Power Transform
幂变换是一类用于减小偏度、稳定方差的变换技术: 使用幂函数; 变换函数是单调 monotonic 的。
幂函数的形式为 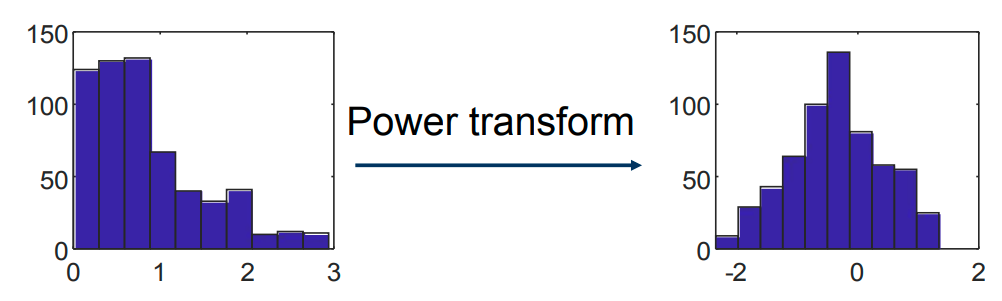
优势 用来稳定数据的方差(减小偏度);
- 减少极端值的影响;
- 得不同区间上的方差更一致,不再强烈依赖于
。
使数据分布更接近高斯分布;
- 许多机器学习模型在接近高斯分布的数据上表现更好。
为模型评估构建训练集与测试集 Construct Training / Test Sets for Model Evaluation
常用于构建训练集和测试集的方法:
- 单一划分 A single training and test set
- 考虑分层采样 Consider stratification
- K 折交叉验证 K-fold cross-validation
- 留一法交叉验证 Leave-one-out cross-validation
将完整数据集随机划分为训练集和测试集 在模型评估中的好处:
在模型评估中的好处:
- 有一个独立的测试集,评价较为无偏 unbiased;
- 可帮助发现并避免过拟合模型。
多类别情况下的分层采样 Stratified sampling (multiple classes)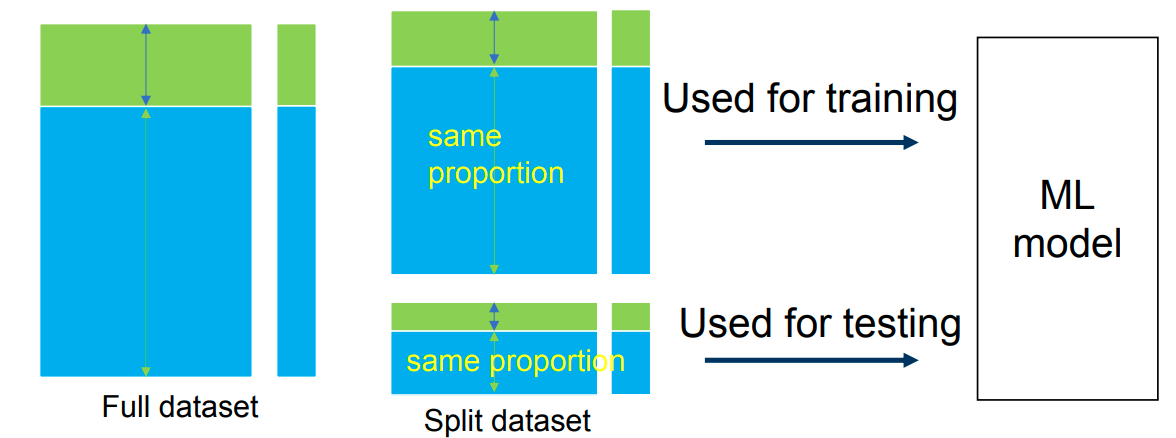 好处
好处
- 防止样本分布偏差;
- 降低评估结果的方差。
做法
- 对每个类别分别进行随机抽样,保证训练集和测试集中各类别所占比例与原始数据集相同。
交叉验证 Cross-validation
K-fold cross validation
 将数据集划分为多个子集或折(subsets or folds); 每次取其中 k−1 折作为训练集,剩下 1 折作为测试集来训练和评估模型; 轮流把每一折都作为测试集,直到所有折都被用作过测试集。
将数据集划分为多个子集或折(subsets or folds); 每次取其中 k−1 折作为训练集,剩下 1 折作为测试集来训练和评估模型; 轮流把每一折都作为测试集,直到所有折都被用作过测试集。
优势
- 减少因为一次随机划分导致的偶然误差;
- 提供更稳健的性能评估;
- 最大化地利用了全部数据。
缺陷
- 训练时间更长;
- 实现上更复杂。
留一交叉验证 Leave-one-out cross-validation
留一交叉验证是 k 折交叉验证的极端情况,此时 
- 数据集中每一个样本单独作为一折;
- 每次用 k−1 个样本训练模型,剩下的 1 个样本用来测试;
- 轮流将每个样本都作为测试样本。